It is the process of grouping documents such that documents in a cluster are similar and documents in different cluster are dissimilar. Vector space model is used.
Algorithm
Find distance of each object to cluster center and assign it to one with minimum
Calculate mean of each cluster group to compute new cluster centers
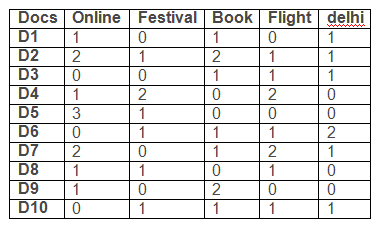
Let k=3 an initial cluster seeds be d2, d5 and d7.
calculating Euclidean distance between d1 and d2 :

The clusters are:
d2, d1, d6, d9, d10
d5, d8
d7, d3, d4
Algorithm
- Choose the value of k
- K objects are randomly chosen to form centroid of k clusters
- Repeat until no change in location of centroid or no change in objects assigned to cluster
Find distance of each object to cluster center and assign it to one with minimum
Calculate mean of each cluster group to compute new cluster centers
Let k=3 an initial cluster seeds be d2, d5 and d7.
calculating Euclidean distance between d1 and d2 :
The clusters are:
d2, d1, d6, d9, d10
d5, d8
d7, d3, d4
If you want something and you get something else, never be afraid. One day things will surely work your way!!
No comments:
Post a Comment