Tom is planning to buy a smartphone. He searches online but finds different brands with the same specifications. He even puts a Facebook post asking for suggestions. Accidentally he notices 'DigiShopiGo' web store. 'DigiShopiGo' is a world famous retail chain offering wide variety of products. Tom decides to search for the smartphone in the web store.
The first step to search for a product in 'DigiShopiGo' is to register the email-id. After registering Tom sees variety of models with the same specifications which his friends had bought. He could also see reviews of the product. Tom purchases the product. He gets intimations regarding the delivery of the product. To his surprise a drone delivered the purchased mobile in 30 minutes. Tom receives the product. He is very much satisfied with his experience in purchasing the product and shares his opinion in social media.
'DigiShopiGo' has an advanced analytics wing that keeps track of the social media activities of its customers. Identifying Tom's opinion as Positive feedback, It starts sending intimations to Tom regarding the sale and availability of mobile accessories.
Accidentally Tom loses his mobile charger. He searches for an electronics shop online and offline. Suddenly he gets an intimation regarding the 'DigiShopiGo' outlet just nearby. 'DigiShopiGo' uses shopper's location data to showcase the nearest retail location. On entering the store, Tom was astonished to see a map showing the exact location of the item he needs to buy.Tom also gets instant notifications regarding the estimated wait time at the store for billing. As Tom walks he could also see smart digital shelves that gives him a personalized experience highlighting products of his interest. He instantly shares the experience in social media. So being digital means being social and accessible.
Be where the world is going!
Facebook’s AI research team(FAIR) has been working on the problem of object detection by using deep learning to give computers the ability to reach conclusions about what objects are present in a scene. The company’s object detection algorithm, based on the Caffe2 deep learning framework, is called Detectron. The Detectron project was started in July 2016 with the goal of creating a fast and flexible object detection system. It implements state-of-the-art object detection algorithms. It is written in Python and powered by the Caffe2 deep learning framework. The algorithms examine video input and are able to make guesses about what discrete objects comprise the scene.
At FAIR, Detectron has enabled numerous research projects, including:
- Feature Pyramid Networks for Object Detection: Feature pyramids are a basic component in recognition systems for detecting objects at different scales. But it is not currently recommended due to its compute and memory intensive nature.
- Mask R-CNN: It is a general framework for object instance segmentation. In object instance segmentation, given an image, the goal is to label each pixel according to its object class as well as its object instance. Instance segmentation is closely related to two important tasks in computer vision, namely semantic segmentation and object detection. The goal of semantic segmentation is to label each pixel according to its object class. However, semantic segmentation does not differentiate between two different object instances of the same class. For example, if there are two persons in an image, semantic segmentation will assign the same label to pixels belonging to either of these two persons. The goal of object detection is to predict the bounding box and the object class of each object instance in the image. However, object detection does not provide per-pixel labeling of the object instance. Compared with semantic segmentation and object detection, object instance segmentation is strictly more challenging, since it aims to identify object instance as well as provide per-pixel labeling of each object instance.
- Detecting and Recognizing Human-Object Interactions: To understand the visual world, a machine must not only recognize individual object instances but also how they interact. The Human-Object interaction is detected and represented as triplets<human, verb, object> in photos. Eg: <person, reads, book>
- Focal Loss for Dense Object Detection: The highest accuracy object detectors to date are based on a two-stage approach popularized by R-CNN, where a classifier is applied to a sparse set of candidate object locations. In contrast, one-stage detectors that are applied over a regular, dense sampling of possible object locations have the potential to be faster and simpler, but have trailed the accuracy of two-stage detectors. An object detector named Retinanet is designed to identify the loss. RetinaNet is able to match the speed of previous one-stage detectors while surpassing the accuracy of all existing state-of-the-art two-stage detectors.
- Non-local Neural Networks: Non-local means is an algorithm in image processing for image denoising. Unlike "local mean" filters, which take the mean value of a group of pixels surrounding a target pixel to smooth the image, non-local means filtering takes a mean of all pixels in the image, weighted by how similar these pixels are to the target pixel. This results in much greater post-filtering clarity, and less loss of detail in the image compared with local mean algorithms. Inspired by the classical non-local means method in computer vision, the non-local operation computes the response at a position as a weighted sum of the features at all positions. This building block can be plugged into many computer vision architectures.
- Learning to Segment Every Thing: Existing methods for object instance segmentation require all training instances to be labeled with segmentation masks. This requirement makes it expensive to annotate new categories and has restricted instance segmentation models to ~100 well-annotated classes. A new partially supervised training paradigm is proposed, together with a novel weight transfer function, that enables training instance segmentation models over a large set of categories for which all have box annotations, but only a small fraction have mask annotations.
- Data Distillation: Omni-supervised learning is a special area of semi-supervised learning in which the learner exploits all available labeled data plus internet-scale sources of unlabeled data. Data distillation is a method that ensembles predictions from multiple transformations of unlabeled data, using a single model, to automatically generate new training annotations.
The goal of Detectron is to provide a high-quality, high-performance codebase for object detection research. It is designed to be flexible in order to support rapid implementation and evaluation of novel research. Detectron includes implementations of the following object detection algorithms:
- Mask R-CNN
- RetinaNet
- Faster R-CNN
- RPN
- Fast R-CNN
- R-FCN
From augmented reality to various computer vision tasks, Detectron has a wide variety of uses. One of the many things that this new platform can do is object masking. Object masking takes objected detection a step further and instead of just drawing a bounding box around the image, it can actually draw a complex polygon. Detectron is available under the Apache 2.0 licence at GitHub. The company says it is also releasing extensive performance baselines for more than 70 pre-trained models that are available to download from its model zoo on GitHub. Once the model is trained, it can be deployed on the cloud and even on mobile devices.
References
- https://www.techleer.com/articles/469-facebook-announces-open-sourcing-of-detectron-a-real-time-object-detection/
- https://github.com/facebookresearch/Detectron
- https://arxiv.org/
Success is walking from failure to failure with no loss of enthusiasm..
It is the process of grouping documents such that documents in a cluster are similar and documents in different cluster are dissimilar. Vector space model is used.
Algorithm
- Choose the value of k
- K objects are randomly chosen to form centroid of k clusters
- Repeat until no change in location of centroid or no change in objects assigned to cluster
Find distance of each object to cluster center and assign it to one with minimum
Calculate mean of each cluster group to compute new cluster centers
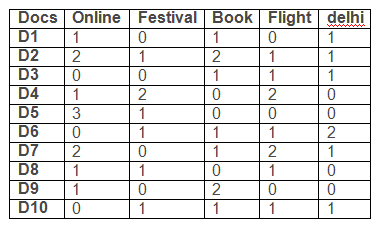
Let k=3 an initial cluster seeds be d2, d5 and d7.
calculating Euclidean distance between d1 and d2 :
The clusters are:
d2, d1, d6, d9, d10
d5, d8
d7, d3, d4
If you want something and you get something else, never be afraid. One day things will surely work your way!!
Google AIY Vision Kit
Google has introduced the AIY Voice Kit back in May, and now the company has launched the AIY Vision Kit that has on-device neural network acceleration for Raspberry Pi. Unlike the Voice Kit, the Vision Kit is designed to run the all the machine learning locally on the device rather than talk to the cloud. While it was possible to run TensorFlow locally on the Raspberry Pi with the Voice Kit, the previous kit was far more suited to using Google’s Assistant API or their Cloud Speech API to do voice recognition. However the Vision Kit is designed from the ground up to run do all its image processing locally. The Vision kit includes a new circuit board, and computer vision software can be paired with Raspberry Pi computer and camera.
In addition to the Vision, users will need a Raspberry Pi Zero W, a Raspberry Pi Camera, an SD card and a power supply, that must be purchased separately. The Kit includes cardboard outer shell, the VisionBonnet circuit board, an RGB arcade-style button, a piezo speaker, a macro/wide lens kit, a tripod mounting nut and other connecting components.
The main component of the Vision Kit is the VisionBonnet that features the Intel Movidius MA2450 which is a low-power vision processing unit capable of running neural network models on-device. The software includes three models:
- Model to recognize common objects
- Model to recognize faces and their expressions
- Person, cat and dog detector
Google has also included a tool to compile models for Vision Kit, and users can train their own models with Google’s TensorFlow machine learning software. The AIY Vision kit costs $44.99 and will ship from December 31st through Micro Center. This first batch is a limited run of just 2,000 units and is available in the US only.
AWS Deeplens
Amazon’s Deeplens device introduced at Amazon ReInvent is aimed, at software developers and data scientists using machine learning, and Amazon have packed a lot of power into it a 4 megapixel camera that can capture 1080P video, a 2D microphone array, and even an Intel Atom processor. Intended to sit connected to the mains and be used as a platform, as a tool. It’s a finished product, with a $250 price. It will be shipped only after April 2018. DeepLens uses Intel-optimized deep learning software tools and libraries (including the Intel Compute Library for Deep Neural Networks, Intel clDNN) to run real-time computer vision models directly on the device for reduced cost and real-time responsiveness. It supports major machine learning frameworks like Google’s TensorFlow, Facebook’s Caffe2, Pytorch, and Apache MXNET. DeepLens will be tightly integrated with other cloud and AI services sold by AWS.
The Amazon kit is aimed at developers looking to build and train deep learning models in the real world. The Google kit is aimed at makers looking to build projects, or even products. The introduction of TensorflowLite and the Google AIY Vision kit can be regarded as a recent trend in moving the computation to the device rather than the cloud.
Reference:
https://aiyprojects.withgoogle.com/
https://aws.amazon.com/deeplens/
https://aws.amazon.com/blogs/aws/deeplens/
Adopting the right attitude can convert a negative stress into a positive one
Doc -> {+, -}
Documents are a vector or array of words
Conditional independence assumption: No relation exists between words and they are independent of each other.
Probability of review being positive is equal to probability of each word classified as positive while going through the entire length of document
Unique words- I, loved, the, movie, hated, a, great, poor, acting, good [10 unique words]
Involves 3 steps:
1. Convert docs to feature sets
2. Find probabilities of outcomes
3. Classifying new sentences
Convert docs to feature sets
Attributes: all possible words
Values: no: of times the word occurs in the doc
Find Probabilities of outcomes
P(+)=3/5=0.6
No: of words in + case(n)=14
No: of times word k occurs in these cases + (nk)
P(wk | +) =(nk + 1) /(n+|vocabulary|)
P(I|+)=(1+1)/(14+10)=0.0833
P(loved|+)=(1+1)/(14+10)=0.0833
P(the|+)=(1+1)/(14+10)=0.0833
P(movie|+)=(4+1)/(14+10)=0.2083
P(hated|+)=(0+1)/(14+10)=0.0417
P(a|+)=(2+1)/(14+10)=0.125
P(great|+)=(2+1)/(14+10)=0.125
P(poor|+)=(0+1)/(14+10)=0.0417
P(acting|+)=(1+1)/(14+10)=0.0833
P(good|+)=(2+1)/(14+10)=0.125
docs with –ve outcomes
p(-)=2/5=0.4
P(I|-)=(1+1)/(16+10)=0.125
P(loved|-)=(0+1)/(6+10)=0.0625
P(the|-)=(1+1)/(6+10)=0.125
P(movie|-)=(1+1)/(6+10)=0.125
P(hated|-)=(1+1)/(6+10)=0.125
P(a|-)=(0+1)/(6+10)=0.0625
P(great|-)=(0+1)/(6+10)=0.0625
P(poor|-)=(1+1)/(6+10)=0.125
P(acting|-)=(1+1)/(6+10)=0.125
P(good|-)=(0+1)/(6+10)=0.0625
Classifying new sentence
Eg: I hated the poor acting
Probability of sentence being positive,
P(+).P(I|+).P(hated|+).P(the|+).P(poor|+).P(acting|+)
0.6*0.0833*0.0417*0.0833*0.0417*0.0833=6.0*10-7
Probability of sentence being negative,
P(-).P(I|-).P(hated|-).P(the|-).P(poor|-).P(acting|-)
0.4*0.125*0.125*0.125*0.125*0.125=1.22*10-5
So the sentence is classified as negative.
If the word is not present in the vocabulary a very tiny probability is assigned to the word.
A calm and modest life brings more happiness than the pursuit of success combined with constant restlessness.
Configuring Spark with Mongo DB
Two packaged connectors are available to integrate Mongo DB and Spark:
- Spark Mongo DB connector developed by Stratio: Spark-MongoDB
- Mongo DB connector for Spark: mongo-spark
Dependencies required are:
- Mongo DB Connector for Spark: mongo-spark-connector_2.10
- Mongo DB Java Driver
- Spark dependencies
Sample Code
Mongoconfig.scala
traitMongoConfig {
val database = "test"
val collection = "characters"
val host = "localhost"
val port = 27017
}
DataModeler.scala
import org.apache.spark.{ SparkConf, SparkContext }
import org.apache.spark.sql.SQLContext
import com.mongodb.spark.config._
import com.mongodb.spark.api.java.MongoSpark
import com.mongodb.spark._
import com.mongodb.spark.sql._
object DataModeler extends MongoConfig {
def main(args: Array[String]): Unit = {
println("Initializing Streaming Spark Context...")
System.setProperty("hadoop.home.dir", """C:\hadoop-2.3.0""")
val inputUri = "mongodb://" + host + ":" + port + "/" + database + "." + collection
val outputUri = "mongodb://" + host + ":" + port + "/" + database + "." + collection
val sparkConf = new SparkConf()
.setMaster("local[*]")
.setAppName("MongoConnector")
.set("spark.mongodb.input.uri", inputUri)
.set("spark.mongodb.output.uri", outputUri)
println("SparkConf is set...")
val sc = new SparkContext(sparkConf)
val dataHandler = new DataHandler()
//Data Insertion
dataHandler.insertData(sc)
// Helper Functions
val sqlContext = SQLContext.getOrCreate(sc)
var df = MongoSpark.load(sqlContext)
var rows = df.count()
println("Is collection empty- " + df.isEmpty())
println("Number of rows- " + rows)
println("First row- " + df.first())
//Data Selection
println("The elements are:")
sc.loadFromMongoDB().take(rows.toInt).foreach(println)
//Querying collection using SQLcontext
val characterdf = sqlContext.read.mongo()
characterdf.registerTempTable("characters")
val centenarians = sqlContext.sql("SELECT name, age FROM characters WHERE age >= 100")
println("Centenarians are:")
centenarians.show()
//Applying aggregation pipeline
println("Sorted values are:")
sqlContext.read.option("pipeline", "[{ $sort: { age : -1 } }]").mongo().show()
// Drop database
//MongoConnector(sc).withDatabaseDo(ReadConfig(sc), db =>db.drop())
println("Completed.....")
}
}
DataHandler.scala
import org.apache.spark.SparkContext
import com.mongodb.spark.api.java.MongoSpark
import org.bson.Document
class DataHandler {
def insertData(sc: SparkContext) {
val docs = """
|{"name": "Bilbo Baggins", "age": 50}
|{"name": "Gandalf", "age": 1000}
|{"name": "Thorin", "age": 195}
|{"name": "Balin", "age": 178}
|{"name": "Kíli", "age": 77}
|{"name": "Dwalin", "age": 169}
|{"name": "Óin", "age": 167}
|{"name": "Glóin", "age": 158}
|{"name": "Fíli", "age": 82}
|{"name": "Bombur"}""".trim.stripMargin.split("[\\r\\n]+").toSeq
MongoSpark.save(sc.parallelize(docs.map(Document.parse)))
}
}
Dependencies
Spark-assembly-1.6.1-hadoop2.6.0.jar
Mongo-java-driver-3.2.2.jar
Mongo-spark-connector_2.10-0.1.jar
References
- https://docs.mongodb.com/manual/
- https://docs.mongodb.com/spark-connector
- https://github.com/mongodb/mongo-spark
- https://github.com/Stratio/Spark-MongoDB
- https://www.mongodb.com/mongodb-architecture
- https://jira.mongodb.org/secure/attachment/112939/MongoDB_Architecture_Guide.pdf
Be self motivated, We are the creators of our destiny
Terminologies
Mongo DB Processes and Configurations
- mongod – Database instance
- mongos - Sharding processes
Analogous to a database router.
Processes all requests
Decides how many and which mongods should receive the query
Mongos collates the results, and sends it back to the client.
- mongo – an interactive shell (a client)
Fully functional JavaScript environment for use with a Mongo DB
Getting started with Mongo DB
- To install mongo DB, go to this link and click on the appropriate OS and architecture: http://www.mongodb.org/downloads
- Extract the files
- Create a data directory for mongoDB to use
- Open the mongodb/bin directory and run mongod.exe to start the database server.
- To establish a connection to the server, open another command prompt window and go to the same directory, entering in mongo.exe.
Mongo DB CRUD Operation
1. Create
• db.collection.insert( <document> )
Eg: db.users.insert(
{ name: “sally”, salary: 15000, designation: “MTS”, teams: [ “cluster-management” ] }
)
• db.collection.save( <document> )
2. Read
• db.collection.find( <query>, <projection> )
Eg: db.collection.find(
{ qty: { $gt: 4 } },
{ name: 1}
)
• db.collection.findOne( <query>, <projection> )
3. Update
db.collection.update( <Update Criteria>, <Update Action>, < Update Option> )
Eg: db.user.update(
{salary:{$gt:18000}},
{$set: {designation: “Manager”}},
{multi: true}
)
4. Delete
db.collection.remove( <query>, <justOne> )
Eg: db.user.remove(
{ “name" : “sally" },
{justOne: true}
)
When to Use Spark with MongoDB
While MongoDB natively offers rich analytics capabilities, there are situations where integrating the Spark engine can extend the real-time processing of operational data managed by MongoDB, and allow users to operationalize results generated from Spark within real-time business processes supported by MongoDB.
Spark can take advantage of MongoDB’s rich secondary indexes to extract and process only the range data it needs– for example, analyzing all customers located in a specific geography. This is very different from other databases that either do not offer, or do not recommend the use of secondary indexes. In these cases, Spark would need to extract all data based on a simple primary key, even if only a subset of that data is required for the Spark process. This means more processing overhead, more hardware, and longer time-to-insight for the analyst.
Examples of where it is useful to combine Spark and MongoDB include the following.
1. Rich Operators & Algorithms
Spark supports over 100 different operators and algorithms for processing data. Developers can use this to perform advanced computations that would otherwise require more programmatic effort combining the MongoDB aggregation framework with application code. For example, Spark offers native support for advanced machine learning algorithms including k-means clustering and Gaussian mixture models.
Consider a web analytics platform that uses the MongoDB aggregation framework to maintain a real time dashboard displaying the number of clicks on an article by country; how often the article is shared across social media; and the number of shares by platform. With this data, analysts can quickly gain insight on how content is performing, optimizing user’s experience for posts that are trending, with the ability to deliver critical feedback to the editors and ad-tech team.
Spark’s machine learning algorithms can also be applied to the log, clickstream and user data stored in MongoDB to build precisely targeted content recommendations for its readers. Multi-class classifications are run to divide articles into granular sub-categories, before applying logistic regression and decision tree methods to match readers’ interests to specific articles. The recommendations are then served back to users through MongoDB, as they browse the site.
2. Processing Paradigm
Many programming languages can use their own MongoDB drivers to execute queries against the database, returning results to the application where additional analytics can be run using standard machine learning and statistics libraries. For example, a developer could use the MongoDB Python or R drivers to query the database, loading the result sets into the application tier for additional processing.
However, this starts to become more complex when an analytical job in the application needs to be distributed across multiple threads and nodes. While MongoDB can service thousands of connections in parallel, the application would need to partition the data, distribute the processing across the cluster, and then merge results. Spark makes this kind of distributed processing easier and faster to develop. MongoDB exposes operational data to Spark’s distributed processing layer to provide fast, real-time analysis. Combining Spark queries with MongoDB indexes allows data to be filtered, avoiding full collection scans and delivering low-latency responsiveness with minimal hardware and database overhead.
3. Skills Re-Use
With libraries for SQL, machine learning and others –combined with programming in Java, Scala and Python –developers can leverage existing skills and best practices to build sophisticated analytics workflows on top of MongoDB.
Don't fear failure in the first attempt because even the successful maths started with 'zero' only